From genome to interactome
Genome, proteome, interactome – since the beginning of the 21st century, the life sciences have been focussing on cataloguing the cell. These days, scientists not only want to identify individual genes and proteins, but also all the genes of one cell (genome), all gene readouts (transcriptome), all proteins (proteome) and their partners (interactome).
Text: Harald Rösch
It all started with the Human Genome Project and the sequencing of our own genetic material in the year 2001. At that time, the diagnosis, prevention and treatment of most, if not all, diseases appeared to be within reach. But the letdown followed soon afterwards. While the decoding of the genome represented a milestone for science, scientists are still far from having a full understanding of all of life’s processes. And, for that reason, medicine has so far benefited far less from the Human Genome Project than had been hoped. While the medical profession now knows about many new genes, for example ones that influence the risk of cancer, diabetes or atherosclerosis, any one of these genes generally only increases the disease risk to a minimal extent. It is difficult to obtain a reliable disease prognosis on that basis. Similarly, the decoded human genome has given rise to hardly any new treatment methods.
It seems that it is not enough to know the sequence of the letters in the genetic code if the aim is to learn how a cell works. The reasons for this can be illustrated using the example of an engineer who wants to recreate a passenger aircraft. First, he or she will need a blueprint for all the individual parts. He or she also needs to know their function, and how they are put together. However, instead of this blueprint, all the engineer has are instructions on how to assemble the individual parts. Thus, he or she knows what the parts are made of, but not what they look like or what function each of them has, let alone how many of each part he needs and how to put them together. It is obvious that the engineer would never be able to build an aircraft under these circumstances.
Biologists are faced with a similar task when attempting to understand the processes of a cell on the basis of genetic data. It is true that the genome provides instructions for the key components of a cell, its proteins. But which proteins will actually be formed, at what point in time and in what quantities - factors that cannot be read quite so easily from the letters of the genetic code.
This is also apparent from the fact that several proteins can often be created from a single gene. That diversity occurs if one gene contains the information for several proteins or if one protein chain is subsequently split into several molecules. Messenger RNA regrouping in the process, known as alternative splicing, can also give rise to different gene products. Thus, up to ten different proteins may go back to a single human gene. For this reason, the number of proteins in a cell may be many times greater than the number of its genes. On the basis of current assumptions that humans have 20,000 to 50,000 genes, scientists estimate that the number of human proteins ranges from 80,000 to 400,000.
This is where the proteome and the interactome come into play. No cell can survive without proteins. They are its molecular motors, frameworks, doors, signalling substances and antennas. Thus, the proteome determines a cell’s task in an organism. If the genome represents the assembly instructions for all the key individual parts, the proteome is the parts catalogue and the interactome the manual showing which parts connect to one another. Consequently, if they can identify the proteins and their reaction partners, researchers hope they will be able to explain the way a cell functions far more accurately, thus also helping them find out the root causes of diseases.
Scientists therefore have high hopes for proteomics. They want to know what proteins are formed by an organism, a tissue, a cell or a cell organelle, and in what quantities. Analogously to the Human Genome Project, the Human Proteome Project is expected to provide new insights into the way that cells function. Moreover, by comparing the proteomes of healthy and diseased cells, researchers could find clues to disease causes. After all, it can take just a single faulty protein to trigger disorders such as cancer, Alzheimer’s or Parkinson’s disease.
But it is not enough just to create this sort of protein catalogue: scientists also need to be familiar with the modifications in the protein molecules which transmit these signals to other molecules. These subsequent changes – thus also referred to as post-translational modifications – often involve small molecules which attach to certain sites on the protein molecule. Examples of these include phosphate, methyl or acetyl groups. Depending on the site at which a protein is phosphorylated, methylated or acetylated, it can activate a particular signalling pathway, thus influencing various metabolic pathways. Therefore, the aim is to carry out an inventory of the proteins with their post-translational modifications.
Now all that is missing is the interactome, i.e. information about the proteins that collaborate with one other. Some proteins come together in pairs and exchange signals in the process. The interactome of a human cell is estimated to comprise about 130,000 such paired interactions. Others, in turn, form complicated organelles out of dozens of proteins, e.g. the ribosomes.
Challenges, setbacks, successes – the story of the Human Proteome Project
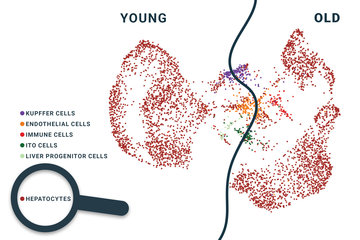
Decoding the human proteome is thus a mammoth task. The technical challenges facing scientists are immense. There are two main reasons for this. One is fundamental in nature: the same genes are not active throughout all the cells of an organism. Depending on cell type, a variety of genes is read out and other proteins formed. Thus, with around 250 different cell types in the human body, there are at least as many proteomes. And that’s not all – a cell’s proteome depends on many other factors. Thus, a cell may form different proteins depending on age, nutritional status or health, so that its protein make-up changes accordingly. Environmental influences such as medicines or toxins also affect the proteome.
Scientists thus need to determine the proteome of each cell type separately. Consequently, years may pass before the full proteome of every human tissue is fully decoded. The Human Proteome Project researchers have therefore set themselves a goal that they can achieve more quickly: to start with, they want to identify one protein that corresponds to each gene. Once that has been done, the proteomes of various cell types, the post-translational changes and the interactome can be worked out by degrees.
The second reason has to do with the chemical properties of proteins. In contrast to DNA molecules, which all exhibit similar chemical behaviour, proteins are extremely variable: some are water-soluble, others fat-soluble. The largest are more than 200 times heavier than the smallest. Some are electrically charged, others are not.
They also occur in very different quantities: some are so plentiful, that protein researchers can harvest them from tissues in large amounts; with others, the scientists have to manage with a few billionths of a milligram. For example, one millilitre of blood contains ten billion times more albumin than interleukins. Consequently, these signalling substances, which occur in such tiny quantities, are particularly difficult to detect and are easily overlooked. But they often have key functions in the cells. Furthermore, proteins cannot be simply copied and replicated like DNA.
All this makes proteome analysis extremely time-consuming and complex. The Human Proteome Organization (HUPO) was therefore established in 2001, with the aim of coordinating proteome research worldwide. In 2004, the Organization initiated a project to analyze blood plasma, but its preliminary results were disappointing. Test studies in which the same tissue sample was analyzed by several groups of researchers resulted in different proteomes. The approaches used were too variable, the analytical methods too error-prone.
After this, the HUPO introduced sampling standards and harmonized data collection and data evaluation. Since then, the Human Proteome Project has advanced significantly, not only as a result of new investigation methods, such as mass spectrometry or cryo-electron tomography techniques specially refined for proteomics, but also due to less aggressive methods of obtaining and purifying proteins from cells and the use of more powerful software for the data analysis. Today, scientists can analyze several thousand proteins in one go.
In contrast to the Human Genome Project, which was founded in the USA in 1990, and in which various national Human Genome Projects were involved, a variety of independent research associations worldwide are working on the Human Proteome Project. Apart from HUPO, which by now has eleven of its own projects, including initiatives to study the brain, kidneys, liver and stem cells, the main association involved in Europe is PROSPECTS – a consortium of eleven research facilities, headed by Matthias Mann from the Max Planck Institute of Biochemistry in Martinsried. The aim of PROSPECTS is to create a catalogue of human proteins along with their structures, interactions and distribution in the cells. The association is also investigating how findings from proteomics can contribute to the treatment of neurodegenerative disorders, such as Alzheimer’s or Parkinson’s disease.