Indo-European languages originate in Anatolia
The Indo-European languages belong to one of the widest spread language families of the world. For the last two millenia, many of these languages have been written, and their history is relatively clear. But controversy remains about the time and place of the origins of the family. A large international team, including MPI researcher Michael Dunn, reports the results of an innovative Bayesian phylogeographic analysis of Indo-European linguistic and spatial data. Their paper 'Mapping the Origins and Expansion of the Indo-European Language Family' appeared this week in Science.


The majority view in historical linguistics is that the homeland of the Indo-European language family was located in the Pontic steppes (present day Ukraine) around 6000 years ago. The evidence for this comes from linguistic paleontology: in particular, certain words to do with the technology of wheeled vehicles are arguably present across all the branches of the Indo-European family; and archaeology tells us that wheeled vehicles arose no earlier than this date. The minority view links the origins of Indo-European with the spread of farming from Anatolia 8000-9500 years ago.
The minority view is decisively supported by the present analysis in this week's Science. This analysis combines a model of the evolution of the lexicons of individual languages with an explicit spatial model of the dispersal of the speakers of those languages. Known events in the past (the date of attestation dead languages, as well as events which can be fixed from archaeology or the historical record) are used to calibrate the inferred family tree against time.

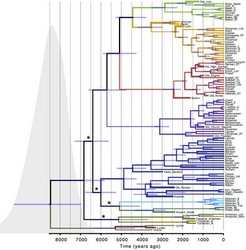
The lexical data used in this analysis come from the Indo-European Lexical Cognacy Database (IELex). This database has been developed in MPI's Evolutionary Processes in Language and Culture group, and provides a large, high-quality collection of language data suitable for phylogenetic analysis. Beyond the intrinsic interest of uncovering the history of language families and their speakers, phylogenetic trees are crucially important for understanding evolution and diversity in many human sciences, from syntax and semantics to social structure.











