Forschungsbericht 2012 - Max-Planck-Institut für Kognitions- und Neurowissenschaften
Wie unser Gehirn Gesicht und Stimme verknüpft
Warum Stimme und Gesicht so wichtig sind
Zwei Prozesse sind von entscheidender Bedeutung für unsere tägliche Interaktion und Kommunikation mit anderen Menschen: Wir müssen die Identität unseres Gesprächspartners erkennen und seine Sprachnachricht verstehen. In unserer alltäglichen Kommunikation stehen uns dafür in der Regel sowohl Gesichts- als auch Stimminformationen zur Verfügung (Abb. 1). Das ist jedoch nicht immer der Fall: Heute kommunizieren wir regelmäßig mithilfe technischer Hilfsmittel, zum Beispiel über Handy, Telefon oder Internet. Zudem befinden wir uns häufig in lauten Umgebungen, in denen Hintergrundgeräusche die Kommunikation erschweren, wie etwa auf Partys oder im Straßenverkehr. In diesen Situationen können wir Identität und Sprachinformationen in erster Linie von nur einer Sinnesmodalität, das heißt, entweder von der Stimme oder von dem Gesicht ableiten. Studien haben jedoch gezeigt, dass unser Gehirn selbst unter diesen Bedingungen Informationen aus beiden Modalitäten nutzen kann. Beispielsweise können wir Stimmen, ohne zusätzliche visuelle Information, besser identifizieren, wenn uns das Gesicht des Sprechers bekannt ist. Dafür gibt es auch eine neurowissenschaftliche Erklärung: Während wir vertraute Stimmen wiedererkennen, werden im Gehirn Areale aktiviert, die beim Erkennen von Gesichtern eine zentrale Rolle spielen [1, 2]. Auch im Bereich der Sprachverarbeitung gibt es Beispiele für solche Verbindungen zwischen Hören und Sehen. So wurde gezeigt, dass beim Lippenlesen Gehirnareale aktiviert werden, die vorrangig akustische Information verarbeiten [3].
![Abb. 1: Modell für die Verarbeitung von Gesichtern und Stimmen während zwischenmenschlicher Kommunikation (nach Modellen von Bruce & Young [4]; von Kriegstein et al. [1]). Wenn wir mit einer anderen Person kommunizieren und dabei ihre Stimme hören oder ihr Gesicht sehen, wird zuerst die Struktur dieser audio-visuellen Information verarbeitet. Diese Information wird genutzt, um (A) die Sprachnachricht zu verstehen und (B) die Identität unseres Gesprächspartners zu erkennen. (C) Im Gehirn wurden Regionen für audio-visuelle Spracherkennung hauptsächlich im Temporallappen (STS: Superior Temporal Sulcus) der linken Gehirnhälfte lokalisiert [1]. (D) Im Gegensatz dazu scheinen Areale für Gesichts- (FFA: Fusiform Face Area) und Stimmerkennung (STS) eher in der rechten Gehirnhälfte zu liegen [1].](/11590552/original-1508156492.jpg?t=eyJ3aWR0aCI6MzQxLCJmaWxlX2V4dGVuc2lvbiI6ImpwZyIsIm9ial9pZCI6MTE1OTA1NTJ9--fb66013056aff1cafd2ad6e9eace2a328bce739e "Abb. 1: Modell für die Verarbeitung von Gesichtern und Stimmen während zwischenmenschlicher Kommunikation (nach Modellen von Bruce & Young [4]; von Kriegstein et al. [1]). Wenn wir mit einer anderen Person kommunizieren und dabei ihre Stimme hören oder ihr Gesicht sehen, wird zuerst die Struktur dieser audio-visuellen Information verarbeitet. Diese Information wird genutzt, um (A) die Sprachnachricht zu verstehen und (B) die Identität unseres Gesprächspartners zu erkennen. (C) Im Gehirn wurden Regionen für audio-visuelle Spracherkennung hauptsächlich im Temporallappen (STS: Superior Temporal Sulcus) der linken Gehirnhälfte lokalisiert [1]. (D) Im Gegensatz dazu scheinen Areale für Gesichts- (FFA: Fusiform Face Area) und Stimmerkennung (STS) eher in der rechten Gehirnhälfte zu liegen [1].")
![Abb. 1: Modell für die Verarbeitung von Gesichtern und Stimmen während zwischenmenschlicher Kommunikation (nach Modellen von Bruce & Young [4]; von Kriegstein et al. [1]). Wenn wir mit einer anderen Person kommunizieren und dabei ihre Stimme hören oder ihr Gesicht sehen, wird zuerst die Struktur dieser audio-visuellen Information verarbeitet. Diese Information wird genutzt, um (A) die Sprachnachricht zu verstehen und (B) die Identität unseres Gesprächspartners zu erkennen. (C) Im Gehirn wurden Regionen für audio-visuelle Spracherkennung hauptsächlich im Temporallappen (STS: Superior Temporal Sulcus) der linken Gehirnhälfte lokalisiert [1]. (D) Im Gegensatz dazu scheinen Areale für Gesichts- (FFA: Fusiform Face Area) und Stimmerkennung (STS) eher in der rechten Gehirnhälfte zu liegen [1].](/11590552/original-1508156492.jpg?t=eyJ3aWR0aCI6MjQ2LCJvYmpfaWQiOjExNTkwNTUyfQ%3D%3D--8b55218fbe8c98b99284077e32a97b56d811a623)
Wie wir Gesichter nutzen, um Stimmen zu erkennen
In traditionellen kognitiven Modellen wurde die Personenerkennung als ein hierarchischer Verarbeitungsprozess beschrieben, der mit einer für visuelle und akustische Informationen getrennt ablaufenden Analyse des sensorischen Inputs beginnt (Abb. 1). Daraufhin würden Gesichter und Stimmen erkannt und Gefühle der Vertrautheit ausgelöst. Erst in einem späteren Stadium, nachdem die Identität der Person bereits erkannt sei, würde die Information von Gesicht und Stimme zusammengeführt. Dem widersprachen jedoch neuere Ergebnisse aus Studien mithilfe funktioneller Magnetresonanztomografie, in denen gezeigt wurde, dass beim Erkennen bekannter Stimmen Hirnareale aktiv werden, die eigentlich Gesichter verarbeiten. Ein gesichtssensitives Areal, englisch Fusiform Face Area, oder FFA, erwies sich als funktionell gekoppelt mit Arealen im oberen Temporallappen, dem Superior Temporal Sulcus, oder STS, die bei der Stimmerkennung involviert sind [2]. Das weist darauf hin, dass Gesichts- und Stimmerkennung schon auf niedriger Verarbeitungsebene interagieren (vgl. Abb. 1 B/D).
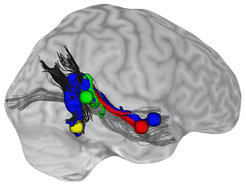
Mithilfe der Traktografie, einer mathematischen Modellierungstechnik, die es ermöglicht, den Verlauf von Nervenfaserbündeln des Gehirns sichtbar zu machen, konnten später auch auf anatomischer Ebene direkte Verbindungen zwischen FFA und STS nachgewiesen werden (Abb. 2, [5]). Stark ausgeprägt waren besonders die Verbindungen der FFA zu den für die Erkennung der Stimmidentität zuständigen mittleren und vorderen Teilen des STS. Zu Arealen im hinteren STS, die eher akustische Merkmale der Stimme extrahieren, war die Verbindung schwächer ausgeprägt. Die Nervenfaserbahnen scheinen also tatsächlich vorrangig dem Informationsaustausch zwischen auditorischer und visueller Personenerkennung zu dienen. Diese Erkenntnisse erweitern die traditionellen Modelle der Personenerkennung und erklären, auf welche Weise gelernte Assoziationen von Gesichtern und Stimmen bei der Personenerkennung selbst dann zusammen genutzt werden können, wenn nur Informationen aus einer Sinnesmodalität zur Verfügung stehen. Im Alltag könnte uns dies dabei helfen, vertraute Personen schnell und unter widrigen Bedingungen zu identifizieren.
 und dem Gesichtserkennungsareal (gelbe Kugel) bestehen direkte strukturelle Verbindungen. Im Vergleich dazu ist die Verbindung zum für allgemeinere akustische Information zuständigen Areal (grüne Kugel) weniger stark ausgebildet. Die Verbindungen scheinen ein Teil von größeren Nervenfaserbündeln zu sein (gezeigt in grau und schwarz).")
Wie wir akustische Information nutzen, um Lippenlesen zu verbessern
Auch bei der Sprachverarbeitung verwenden wir wenn möglich visuelle Information, um unser Sprachverständnis zu unterstützen [6]. Eine Form, visuelle Sprachinformationen zu nutzen, ist das Lippenlesen. Dabei handelt es sich um einen sehr anspruchsvollen Prozess, bei dem es große individuelle Unterschiede gibt. Die Fähigkeit, von den Lippen zu lesen, kann einerseits durch zusätzliche akustische Informationen verbessert und beeinflusst werden, andererseits durch visuelle Vorinformation, indem man etwa auf den Gegenstand zeigt, über den gesprochen wird.
Im Gehirn ist ein Netzwerk von Regionen für das Lippenlesen relevant. Eine Region im linken hinteren STS scheint besonders wichtig für den Abgleich von visueller und akustischer Information zu sein: Sie zeigt erhöhte Aktivität, wenn akustische Vorinformation nicht mit der visuellen Sprachinformation übereinstimmt. Bei besseren Lippenlesern fällt dieses Fehlersignal besonders stark aus (Abb. 3, [7]). Interessant ist, dass auch hier zwischen auditorischen und visuellen Spracharealen im STS eine funktionelle Verbindung besteht. Auch in diesem Fall könnten direkte Verbindungen zwischen auditorischen und visuellen Arealen es unserem Gehirn ermöglichen, Vorinformationen zu nutzen, um Lippenlesen zu optimieren.
 reagierte mit erhöhter Aktivität, wenn beim Lippenlesen die Mundbewegung nicht mit erwarteten Wörtern zusammenpasste. Dieses Areal war funktionell mit einem auditorischen Sprachareal im vorderen/mittleren STS (rot) verbunden.")

Wie wir dieses Wissen nutzen können
Hirnregionen, die auf die Verarbeitung von Stimmen und Gesichtern spezialisiert sind, arbeiten während der Personenerkennung und des Verstehens von Sprache eng zusammen. Studien der letzten Jahre haben das Wissen über die zugrunde liegenden Prozesse vermehrt. Die Ergebnisse können auch dazu beitragen, Defizite in der Personenerkennung, wie etwa Prosopagnosie (http://www.prosopagnosie.de/) oder Phonagnosie (http://phonagnosie-test.cbs.mpg.de/), die Unfähigkeit, andere an Gesicht oder Stimme zu erkennen, besser zu verstehen. In einem weiteren Bereich der klinischen Anwendung könnten sie zur Entwicklung wirksamer Behandlungen und Kompensationsstrategien für hörgeschädigte Menschen beitragen.